CPU node에서 Python 코드 실행하기
R 사용자는 Step 1-3을 숙지한 뒤 다음 문서로 넘어가세요.
Step 1 - terminal 앱 고르기
User는 SSH로 proxy node에 접속하여 클러스터를 사용합니다. 터미널 환경과 vi 에디터에 익숙한 user는 자신에게 친숙한 앱을 사용하면 됩니다. 그렇지 않은 경우 Visual Studio Code를 사용하는 것을 추천합니다. 이 문서에서는 Visual Studio Code를 사용하는 것을 전제로 합니다. 추천 이유는 다음과 같습니다.
- Windows, MacOS, Linux에서 모두 사용 가능합니다.
- 터미널과 에디터, 파일 브라우저가 통합되어 있습니다.
- 불편하게
vi나nano등의 CLI용 텍스트 에디터를 사용할 필요가 없습니다. - 파일 전송시
scp등의 복잡한 프로토콜을 사용하지 않고 drag & drop으로 수행할 수 있습니다.
- 불편하게
Visual Studio Code외에 다른 앱을 사용하실 경우 추천하는 앱은 다음과 같습니다.
- Windows 10: WSL2(Windows Subsystem for Linux 2)와 Windows Terminal을 설치하여 사용하는 것을 추천합니다.
- MacOS: 기본 터미널을 사용해도 되지만, iTerm2를 추천합니다.
- iOS: 5번 문서를 참조하세요.
- Android: Termux
proxy node
proxynode는 user가 로그인하여 파일을 정리하고cpu-compute나gpu-computenode에 job을 제출하는 용도로만 쓰는 컴퓨터입니다.- 따라서
proxynode는 성능이 낮습니다.proxynode에서는 Python 작업 등을 실행하지 마세요.
- 따라서
- 터미널에서
SSH접속만 할 수 있다면 어떤 기기에서도proxynode에 접속하여 job을 제출할 수 있습니다. - 일단 job을 제출하면, 터미널이 종료되고 user와
proxynode 간의 연결이 끊겨도 job은 계속cpu-compute나gpu-computenode에서 실행됩니다. - Standard output(Python, R에서 console에 출력되는 메시지)이 로그 파일에 기록되므로, 나중에 다시 터미널에 접속하여 job 실행 현황을 확인할 수 있습니다.
Step 2 - proxy node SSH 접속
Visual Studio Code를 설치하고 아래 안내에 따라 설정합니다.
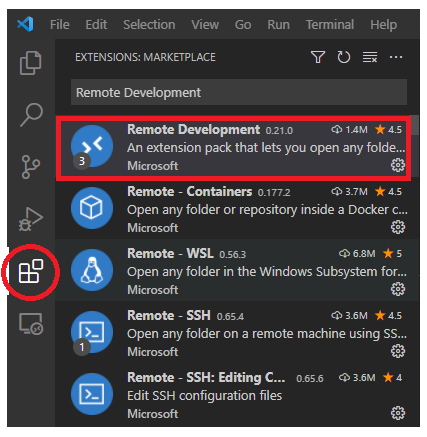
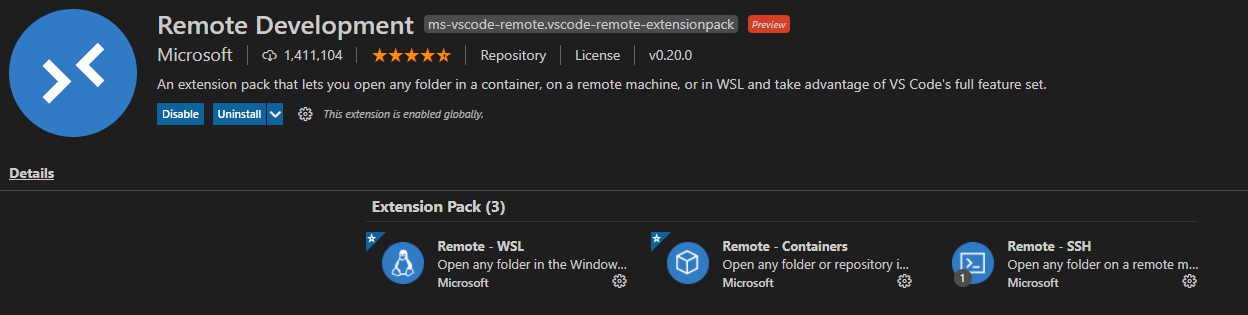
1. Visual Studio Code extensions에서 Remote Development 설치1
Microsoft가 제공하는 Remote Development extension pack을 설치합니다. Remote-WSL, Remote-Containers, Remote-SSH가 자동적으로 같이 설치됩니다.
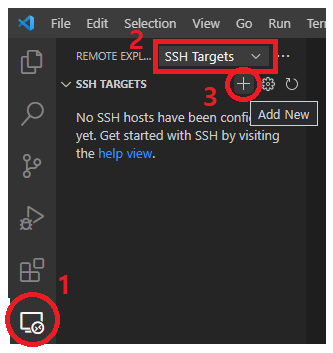
2. Remote Explorer에서 SSH Targets를 선택 후, Add New 클릭
3. ssh 접속 커맨드 입력
아래와 같은 창이 뜨면 SSH 커맨드를 입력하여 proxy node에 접속합니다.

아래 커맨드에 Slack으로 안내받은 port, username을 넣어서 위 창에 입력하고 Enter키를 누르면 됩니다. SSH의 default port는 22이지만, 저희는 보안상 이유로 다른 port를 사용합니다.
|
|
또는 안내받은 proxy node의 ip를 입력해도 됩니다.
|
|
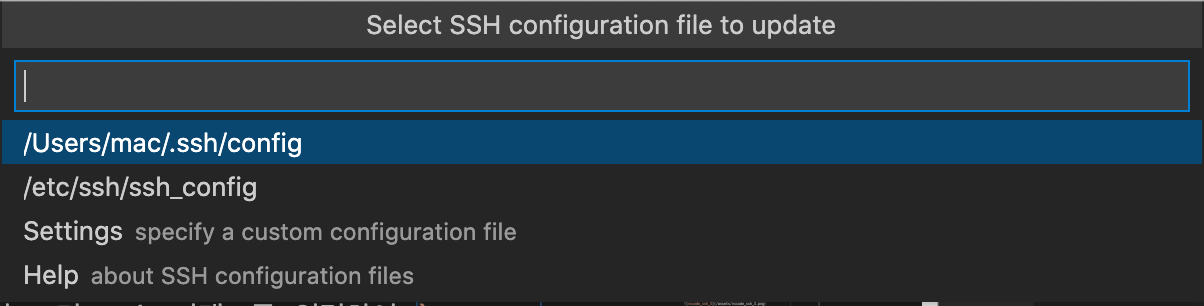
4. SSH configuration file을 저장할 장소 선택
Select SSH configuration file to update가 나오면 맨 위 항목을 선택합니다.
Host added! 라는 메시지가 우측 하단에 나옵니다.

5. Remote Explore에서 Connect to Host in New Window 선택
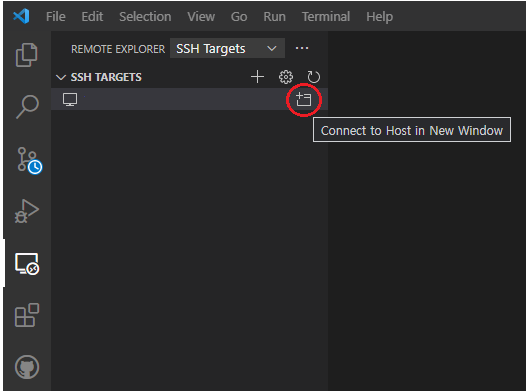
6. 서버 Platform 선택
Linux를 선택합니다.

7. Password 입력
안내받은 password를 입력하여 로그인합니다.

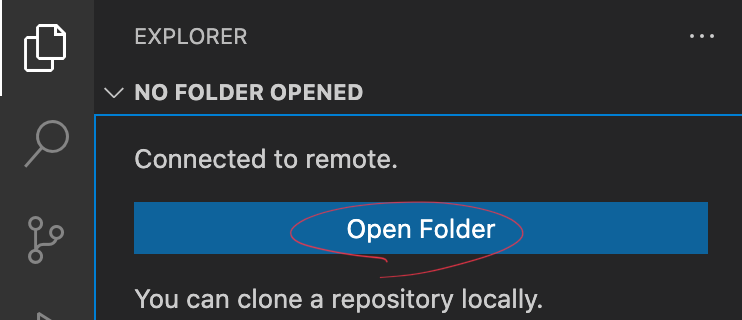
8. 파일 시스템 마운트
좌측 탭의 파일 모양 아이콘을 클릭하고 Open Folder 버튼을 클릭합니다.
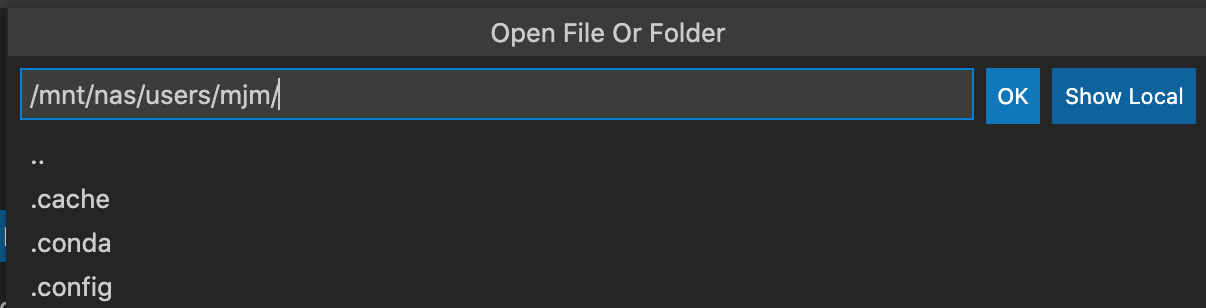
기본적으로 user home directory 경로가 입력되어 있습니다. OK를 누릅니다.
9. 둘러보기
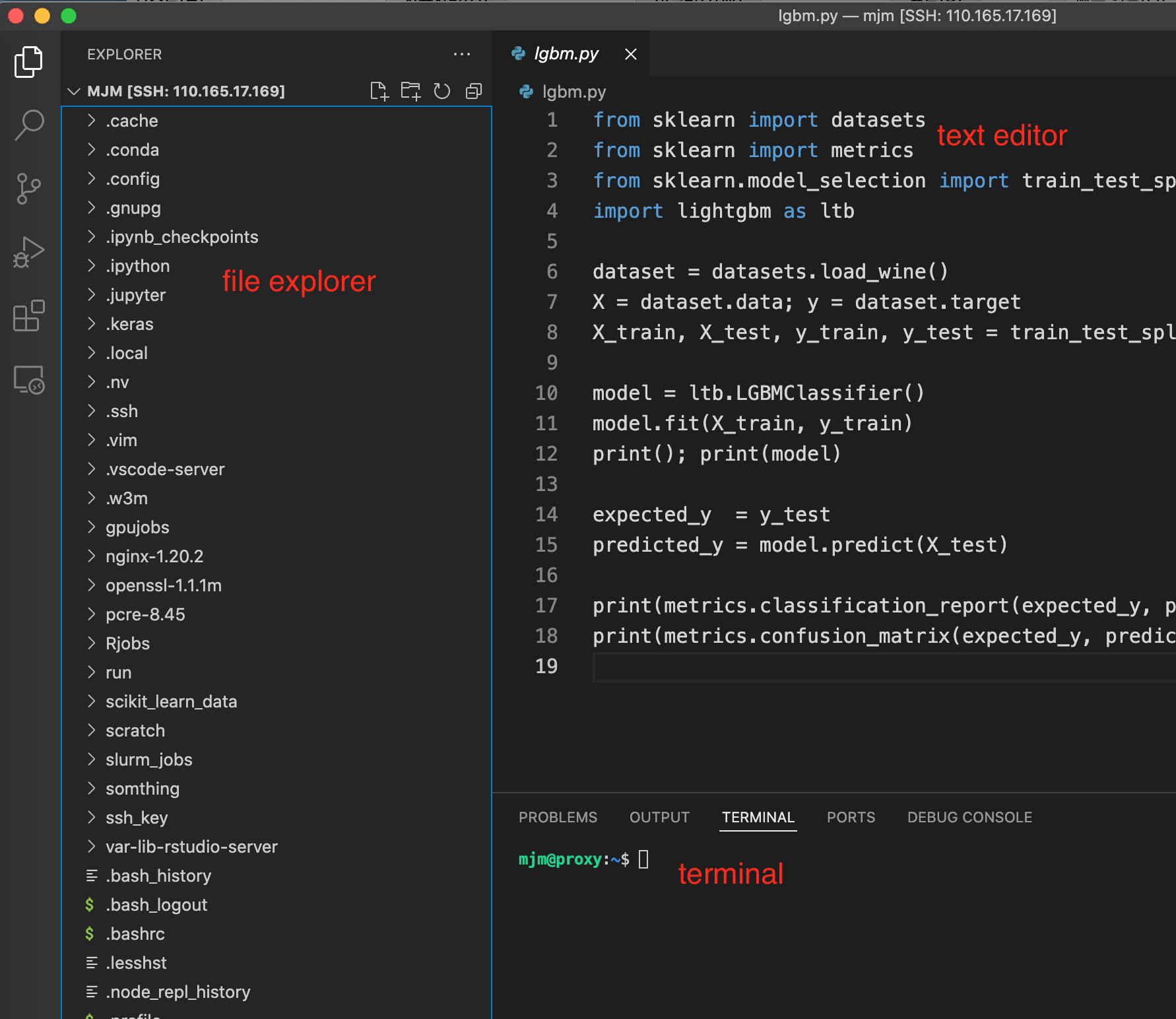
-
좌측 file explorer에서 파일을 관리합니다. Windows 탐색기나 MacOS Finder에서 drag&drop으로 파일을 옮길 수 있습니다. 클러스터 내부의 파일을 user의 local 컴퓨터로 가져오는 것도 drag&drop으로 가능합니다.
-
ctrl + shift + ~키를 누르면 터미널이 열립니다. 여기서 서버 사용에 필요한 커맨드를 입력합니다. 터미널은 여러 개 띄울 수 있습니다. -
text editor에서 코드와 스크립트를 수정하고 이미지 파일 등을 열람합니다.
10. user password 변경
모든 user의 초기 password가 다 동일하기 때문에, 각 user는 첫 접속 시 password를 변경할 것을 권장합니다. 터미널에서 아래 커맨드를 입력하여 password를 변경합니다.
|
|
Step 3. 파일 시스템 구조 이해
NAS(Network Attached Storage)에 각 user의 home directory가 있습니다. NAS는 모든 node에 마운트되어 있으며, 모든 node에서 user명과 group명 및 관련 설정이 동일합니다. User명은 컴퓨팅 클러스터 사용 신청시 제출하신 이메일 주소의 @ 앞 부분과 동일합니다.
User home directory의 prefix는 /mnt/nas/users/입니다. 예를 들어, dummyuser라는 user의 home directory의 경로는 /mnt/nas/users/dummyuser/입니다. 다른 user의 home directory를 열람할 수 없도록 권한설정이 되어 있습니다. 각 user는 데이터와 코드, 설정 파일 등을 자신의 home directory 내에 저장합니다.
- Linux에서 directory를 이동하는 명령어는
cd입니다. - home directory를 나타내는 기호는
~입니다. - 현재 directory를 확인하는 명령어는
pwd입니다 - 파일 목록을 확인하는 명령어는
ls입니다.
따라서 user는 proxy node아래의 명령어를 통해 자신의 홈 directory로 이동해 그 안에 있는 파일 목록을 확인할 수 있습니다.
|
|
Step 4. Conda environment 생성
cpu-computenode에는 conda version 4.11.0이 설치되어 있으며 Python version을 3.10까지 지원합니다2.gpu-computenode에는 conda version 4.6.14가 설치되어 있으며 Python version을 3.8까지 지원합니다.
Step 4.1. Conda environment 생성 batch script 작성
여기서는 cpu-compute node에서 conda environment를 생성하는 방법을 설명합니다. 두 가지 방법 중 하나를 선택하여 진행합니다.
- 4.1.1. 직접 파이썬 버전과 설치할 패키지 목록을 명시해서 생성
- 4.1.2. yml 파일을 통해 생성
4.1.1. 직접 파이썬 버전과 설치할 패키지 목록을 명시해서 생성
Conda environment 생성 slurm batch script를 작성합니다. 아래는 script 예시입니다.
|
|
conda install -y 뒤에 설치를 원하는 패키지명을 입력합니다. 위 내용에서
- 2번 라인의 #SBATCH –job-name=testEnv의 job name을 원하는 이름으로 변경합니다.
- 3번 라인의 #SBATCH –time=99:59:59 은 작업 시간 최대 허용치를 의미합니다.
- 7번 라인의 #SBATCH –output=testEnv.log의 output log 파일명과 경로, 8번 라인의 #SBATCH –error=testEnv.err의 error log 파일명과 경로를 원하는 데로 변경합니다.
- 10번 라인의 environment name을 원하는 이름으로 변경합니다.
- environment 저장 경로를 바꾸고 싶을 경우 11번 라인의 ENV_PATH=/mnt/nas/users/$(whoami)/.conda/envs/$ENV_NAME 에서 $(whoami)와 $ENV_NAME 사이 내용을 원하는 경로로 변경합니다. 이렇게 경로를 바꿀 경우, Python 코드를 실행하는 job을 제출할 때 바뀐 ENV_PATH를 써 주어야 합니다.
- 13번 라인의 python version을 원하는 버전으로 변경합니다.
- 15번 라인의 패키지 설치 커맨드에서 conda install -y 뒤에 설치를 원하는 패키지 이름을 입력합니다.
위 내용에 따라 job script를 알맞게 수정하여 Visual Studio Code에서 작성한 뒤, 클러스터 내 user home directory에 [your_env_name].job으로 저장합니다(e.g. testEnv.job).
4.1.2. yml 파일을 이용해 생성
아래는 yml 파일을 이용해 environment를 생성하는 scipt 예시입니다.
|
|
- #SBATCH –output, #SBATCH –error를 원하는 경로와 파일명으로 변경합니다.
- environment 저장 경로를 바꾸고 싶을 경우 cd /mnt/nas/users/$(whoami)/.conda/envs/ 에서 $(whoami) 뒷부분을 원하는 경로로 변경합니다. 이렇게 경로를 바꿀 경우, Python 코드를 실행하는 job을 제출할 때 바뀐 ENV_PATH를 써 주어야 합니다.
- conda env create –file 뒷쪽에 yml 파일 경로를 입력합니다.
Step 4.2. 작성한 스크립트 실행하기.
Visual Studio Code 하단 터미널에
|
|
를 입력해 slurm batch job submission을 수행합니다. 작업이 노드에서 성공적으로 실행되면
|
|
와 같은 메시지가 뜨고 job 번호가 할당됩니다. 할당되는 job 번호는 나중에 squeue를 통해 정보를 확인하거나 job을 취소할 때 이용되므로 기록해 놓아야 합니다.
|
|
커맨드를 통해 작업 실행 현황을 확인할 수 있습니다.
또는 아래 커맨드를 통해 실시간(1초 단위)으로 작업 실행 현황을 확인할 수 있습니다. ctrl+c로 escape 할 수 있습니다.
|
|
다음 커맨드를 통해 output log, error log파일의 내용을 확인할 수 있습니다.
log 파일의 내용을 다음 커맨드를 통해 실시간으로 확인할 수 있습니다. ctrl+c로 escape할 수 있습니다.
터미널을 여러 개 띄워 놓고 각각에 smap과 tail 커맨드를 입력하면 편리하게 실행 상황을 모니터링할 수 있습니다.
위 샘플 코드는 약 3분 안에 작업이 완료됩니다. smap에서 작업 목록이 사라진 후 cat으로 로그 파일을 열어서
와 같은 기록이 남아 있으면 conda environment 생성이 완료된 것입니다.
작업이 끝나기 전에 취소하려면 scancel 커맨드를 사용합니다.
|
|
가상환경을 생성한 후에 패키지를 추가로 설치할 때는 위의 job script에서 가상환경을 삭제하고 다시 만드는 부분
을 삭제하고 아래와 같이 패키지를 설치하는 커맨드를 추가해 준 다음 job을 제출합니다. -y는 설치 중간에 yes/no 를 물을 경우 자동으로 yes를 입력하게 하는 옵션입니다. 설치 중에 컴퓨터를 직접 조작할 수 없기 때문에 꼭 사용해야 하는 옵션입니다. 아래는 pyyaml 패키지를 설치하는 job script 예시입니다.
|
|
가상환경 생성 및 패키지 설치 중 일어나는 오류 중 상당수가 Python에서 기본으로 제공하는 패키지를 설치하려 하거나, 설치할 패키지의 이름을 잘못 입력했기 때문에 발생합니다. 예를 들어, 위에서 설치한 pyyaml 패키지는 실제로 Python에서 import할 때는 import yaml로 입력하는데, conda install yaml이라고 job script에 쓸 경우 오류가 발생합니다.
Step 5. Slrum batch script 작성하여 서버에 제출하기
5.1. Python 코드 작성
이제 클러스터에서 실행할 Python 코드를 local에서 작성합니다. 코드가 오류 없이 작동하는지 local에서 확인합니다. 그 후 코드 파일을 user home directory에 옮기거나, Visual Studio Code내에서 작성하여 저장합니다.
아래는 tree 기반 boosting 알고리즘인 LightGBM으로 mnist dataset을 분류하는 코드입니다. Boosting round를 10회 수행하고 학습 결과를 csv파일로 저장합니다3. Batch script를 작성할 때는 알고리즘의 output이 자동으로 저장되지 않으므로 파일로 결과를 저장하는 코드를 포함하는 것이 좋습니다. 단, 콘솔에 출력되는 내용은 output log에 자동으로 기록됩니다. 아래 코드를 python_test_cpu.py로 저장하여 user home directory에 둡니다.
|
|
5.2. 현재 클러스터 자원 사용량 확인
아래 커맨드를 통해 cpu-compute 노드의 cpu와 RAM 사용 현황을 볼 수 있습니다.
|
|
아래와 같은 결과가 나옵니다.
- CPUS의 A/I/O/T는 allocated/idle/other/total을 의미합니다.
- 자신의 job이 바로 실행되기를 원한다면, Slurm batch script를 작성할 때
- RAM 용량을 FREE_MEM보다 적게 설정해야 합니다.
- CPU 코어 개수를 CPUS idle보다 적게 설정해야 합니다.
- 현재 가용 자원보다 더 많은 자원을 요구하는 script를 작성하면, job이 바로 실행되지 않습니다. 대기 상태에 있다가 다른 user들의 job이 끝나고 자원이 반환되면 job이 실행됩니다.
5.3. Slurm batch script 작성
앞선 단계에서 만든 해당 conda environment를 activate하고 코드를 실행하는 Slurm batch script를 작성합니다. 클러스터 소개 페이지의 slurm job configurator를 사용하면 script를 쉽게 작성할 수 있습니다.
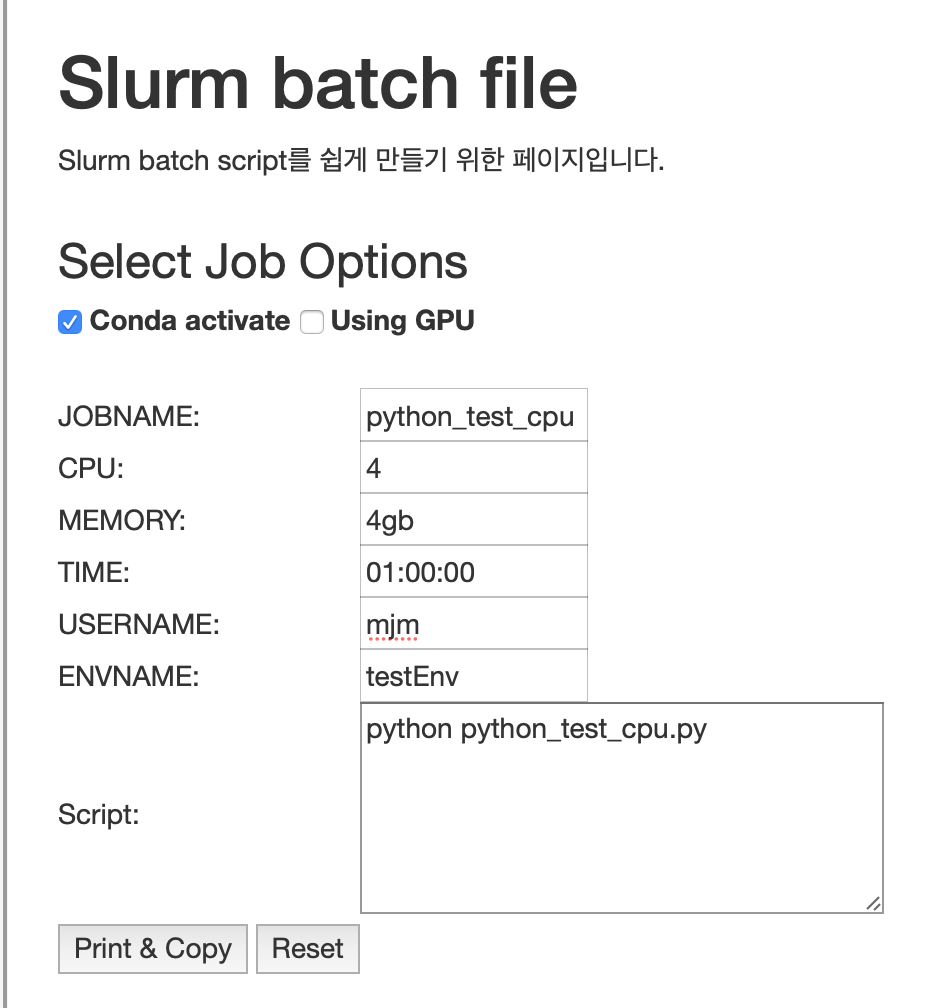
- Conda activate에 체크합니다.
- 빈칸들을 채웁니다. 사용 시간을 넉넉하게 입력할 것을 권장합니다.
- Script란에 python xxx.py라고 작성합니다. 이는 home directory에 있는 xxx.py 파일을 Python으로 실행하라는 의미입니다. Job script를 작성하거나 sbatch 명령어를 사용할 때, visual studio code의 explorer에서 파일명을 마우스 우클릭하고 경로 복사를 사용하면 편리합니다.
- Print & Copy 버튼을 누르면 내용이 클립보드에 복사됩니다.
Slurm batch script의 내용은 아래와 같습니다.
|
|
python_test_cpu.job이라는 이름으로 클러스터의 user home directory에 저장합니다.
Script 윗부분의 #SBATCH 옵션들의 의미는 다음과 같습니다.
- —job-name: 수행할 작업의 이름
- —mem: memory limit
- —nodelist: 작업할 노드의 이름
- —ntasks: 작업의 수
- —cpus-per-task: 각 작업에서 사용할 cpu 코어의 수
- —time: 작업 제한시간
- —account: 해당 작업을 수행하는 계정의 이름
- —partition: group of nodes with specific characteristics
- –nodelist: 사용할 node의 이름
- —output: 코드 실행 결과 log 파일. 확장자는 out이나 log가 가능합니다.
- —error: 코드 실행 결과 log error 파일과 log 파일의 파일명과 저장 경로는 원하는 데로 수정할 수 있습니다. sbatch에 대한 더 자세한 정보는 Slurm 공식 웹페이지를 참조하세요.
5.4. Slurm batch script 실행
Conda environment를 만들 때처럼, sbatch 커맨드를 통해 job을 제출합니다. 할당되는 job 번호는 나중에 squeue를 통해 정보를 확인하거나 job을 취소할 때 이용되므로 기록해 놓아야 합니다.
Step 4에서처럼, ctrl+shift+~를 눌러 터미널을 여러 개 띄우고 smap -i로 작업 현황을 확인하고, tail -f xxx.out, tail -f xxx.err으로 콘솔 출력이나 error를 확인합니다. 작업은 4분 정도 걸립니다.
|
|
현재 작업이 자원을 얼마나 할당받았는지 확인하려면 다음 커맨드를 사용합니다. NumCPUs=4가 코어를 4개 할당받았다는 뜻이고, mem=4G가 RAM을 4gb 할당받았다는 뜻입니다. 이 커맨드는 다른 user가 제출한 job에 대해서도 사용할 수 있습니다.
|
|
|
|
Visual Stuio Code의 file explorer는 실시간으로 변화가 반영되지 않습니다. 새로고침 버튼을 눌러 주면 변화가 반영되고 output 파일이 explorer에 보입니다.
terminal에서는 ssh 접속이 되지만 Visual Studio Code에서는 되지 않을 때
sudo 권한이 필요하므로 조교에게 문의하세요.
해결방법:
로 이 폴더를 사용하는 프로세스 번호를 확인한 후(e.g. 46088)
|
|
그 후 아래 폴더를 삭제합니다.