4. GPU node에서 tensorflow 코드 실행하기#
2번 문서를 먼저 숙지하시기 바랍니다. 이 문서는 2번 문서의 Step 1, 2, 3 이후의 내용만을 다룹니다.
gpu-compute node에서는 Python만 사용 가능합니다.
Step 4. Setting up a conda environment#
conda environment를 새로 만들면서 cudatoolkit, tensorflow, torch를 설치합니다.
주의:
-
각 사용자의 conda environment에 tensorflow, torch 뿐 아니라 cudatoolkit도 따로 설치됩니다.
-
gpu-compute node와 cpu-compute node는 서로 다른 컴퓨터이므로 한쪽에서 만든 conda environment는 다른 쪽에서 사용할 수 없습니다.
우리 컴퓨터의 gpu와 호환이 검증된 tensorflow-gpu==2.2.0, torch==1.7.1 cudatoolkit=11.0를 설치할 것을 권장합니다. 아래 설명은 다른 버전을 사용하고자 할 경우에만 필요합니다.
설명: 버전 관리#
딥러닝 라이브러리를 사용할 때에는 버전 관리가 중요합니다.
- GPU 드라이버 버전(
515.48.07)
- Python 버전
- CUDA 버전(호환성 표)
- cuDNN, 딥러닝 라이브러리(
tensorflow, pytorch) 버전(호환성 표: tensorflow, pytorch)
이 네 가지 요소의 버전이 서로 호환이 되는 조합으로 conda environment를 생성해야 합니다. gpu-compute node의 GPU 드라이버 버전은 515.48.07으로 고정되어 있지만, 나머지 요소들의 버전은 conda environment마다 다르게 설정할 수 있습니다. 단, Python 버전의 경우 gpu-compute node에는 conda version 4.6.14가 설치되어 있으므로 3.8까지만 지원합니다.
Conda를 이용해 버전을 쉽게 맞출 수 있습니다. 이 문서에서는 이 방법을 사용합니다.
- 주어진 GPU 드라이버 버전(
515.48.07)에 맞게 Python 버전과 딥러닝 라이브러리 버전을 정합니다.
- conda install 명령어에서 버전을 명시해 주면 알아서 CUDA와 cuDNN 버전을 맞춰 줍니다.
Conda environment 생성#
environment를 직접 생성할 수도 있고, yml파일을 이용해 생성할 수도 있습니다.
직접 environment 생성#
이제 2번 문서의 안내를 따라 진행하면 됩니다. 따라서 설명을 생략하고 sbatch script만 제시합니다.
- Slurm job configurator에서
Using GPU에 체크한다는 점만 다릅니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#!/bin/bash
#SBATCH --job-name=testEnvGPU
#SBATCH --nodes=1
#SBATCH --mem=4gb
#SBATCH --partition=all
#SBATCH --time=99:59:59
#SBATCH --nodelist=gpu-compute
#SBATCH --output=testEnvGPU.log
#SBATCH --error=testEnvGPU.err
CONDA_BIN_PATH=/opt/miniconda/bin
ENV_NAME=testEnvGPU #environment 이름
ENV_PATH=/mnt/nas/users/$(whoami)/.conda/envs/$ENV_NAME #environment 저장 경로
$CONDA_BIN_PATH/conda env remove --prefix $ENV_PATH
$CONDA_BIN_PATH/conda create -y --prefix $ENV_PATH python=3.8.13
source $CONDA_BIN_PATH/activate $ENV_PATH
conda install -y tensorflow=2.3.0 pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=10.1 -c pytorch
|
cudatoolkit, cudnn 등이 용량이 커서 시간이 조금 오래 걸립니다.
- #SBATCH –nodelist=gpu-compute 옵션이 GPU 컴퓨터를 사용한다는 의미입니다.
- #SBATCH –time=99:59:59 은 작업 시간 최대 허용치를 의미합니다.
- #SBATCH –output, #SBATCH –error를 원하는 경로와 파일명으로 변경합니다.
- environment 저장 경로를 바꾸고 싶을 경우 ENV_PATH=/mnt/nas/users/$(whoami)/.conda/envs/$ENV_NAME 에서 $(whoami)와 $ENV_NAME 사이 내용을 원하는 경로로 변경합니다. 이렇게 경로를 바꿀 경우, Python 코드를 실행하는 job을 제출할 때 바뀐 ENV_PATH를 써 주어야 합니다.
- conda install -y 뒤에 설치를 원하는 패키지명을 입력합니다.
yml 파일을 이용하여 생성#
1
2
3
4
5
6
7
8
9
10
11
12
|
#!/bin/bash
#SBATCH --job-name=testEnvGPU
#SBATCH --nodes=1
#SBATCH --mem=8gb
#SBATCH --partition=all
#SBATCH --nodelist=gpu-compute
#SBATCH --time=30:50:00
#SBATCH --output=/mnt/nas/users/mjm/testEnvGPU.log
#SBATCH --error=/mnt/nas/users/mjm/testEnvGPU.err
CONDA_BIN_PATH=/opt/miniconda/bin
cd /mnt/nas/users/$(whoami)/.conda/envs/ #environment 저장 경로
conda env create --file /mnt/nas/users/mjm/environment.yml
|
- #SBATCH –output, #SBATCH –error를 원하는 경로와 파일명으로 변경합니다.
- environment 저장 경로를 바꾸고 싶을 경우 cd /mnt/nas/users/$(whoami)/.conda/envs/ 에서 $(whoami) 뒷부분을 원하는 경로로 변경합니다. 이렇게 경로를 바꿀 경우, Python 코드를 실행하는 job을 제출할 때 바뀐 ENV_PATH를 써 주어야 합니다.
- conda env create –file 뒷쪽에 yml 파일 경로를 입력합니다.
Step 5. job script 제출#
1. Python 코드 작성#
이제 클러스터에서 실행할 Python 코드를 local이나 Jupyter에서 작성하고 오류 없이 돌아가는지 확인합니다. 그 후 클러스터의 user home directory에 옮기거나, Visual Studio Code내에서 작성하여 저장합니다.
아래는 TensorFlow 공식 페이지에 게시된 초보자용 문서 코드입니다. Batch script를 작성할 때는 알고리즘의 output이 자동으로 저장되지 않으므로 파일로 결과를 저장하는 코드를 포함하는 것이 좋습니다. 아래 코드에는 결과를 저장하는 코드는 없지만, tensorflow가 학습 과정을 콘솔에 출력하기 때문에 이를 로그 파일에서 볼 수 있습니다. 아래 코드를 tensor.py라는 이름으로 user home directory에 저장합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# tensor.py
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)
|
2. 현재 클러스터 자원 사용량 확인#
gpu-compute의 여유 cpu 코어 개수와 RAM은 문서22번 문서에 있는 방법을 통해 확인합니다.
GPU의 경우 한 user가 하나의 GPU만을 사용하도록 되어 있습니다. 따라서 gpu-compute node는 최대 2명의 user가 사용할 수 있습니다. squeue 커맨드를 통해 gpu-compute node에서 실행 중이거나 실행 대기 중인 job의 개수를 파악합니다.
3. Slurm batch script 작성#
앞선 단계에서 만든 해당 conda environment를 activate하고 코드를 실행하는 Slurm batch script를 작성합니다. 클러스터 소개 페이지의 slurm job configurator를 사용하면 script를 쉽게 작성할 수 있습니다.
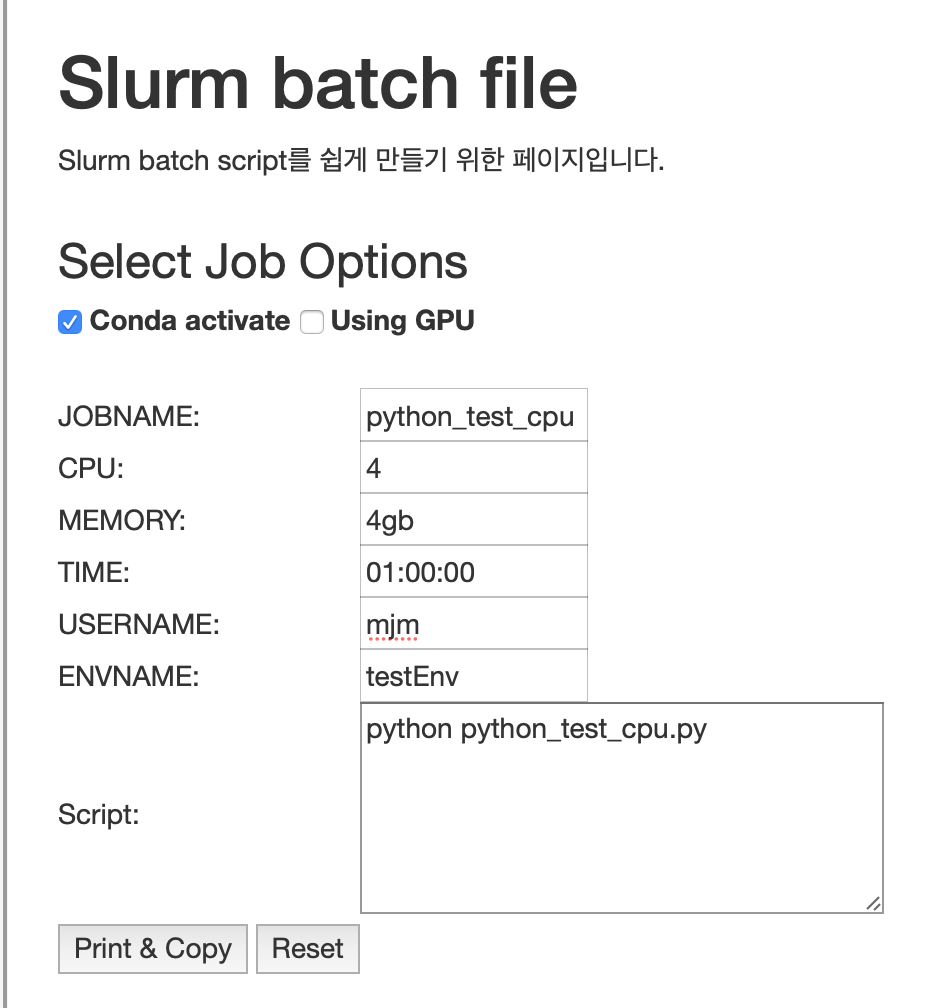
- Conda activate에 체크합니다.
- Using GPU에 체크합니다.
- 빈칸들을 채웁니다.
- Script란에 python xxx.py라고 작성합니다. 이는 home directory에 있는 xxx.py 파일을 Python으로 실행하라는 의미입니다.
- Print & Copy 버튼을 누르면 내용이 클립보드에 복사됩니다.
이 문서에서 사용한 Slurm batch script의 내용은 아래와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#!/bin/bash
#
#SBATCH --job-name=tensor
#SBATCH --partition=all
#SBATCH --account=mjm
#SBATCH --mem=16gb
#SBATCH --ntasks=1
#SBATCH --cpus-per-task=8
#SBATCH --time=00:30:00
#SBATCH --output=/mnt/nas/users/mjm/tensor.log
#SBATCH --error=/mnt/nas/users/mjm/tensor.err
#SBATCH --gres=gpu:1
#SBATCH --nodelist=gpu-compute
CONDA_BIN_PATH=/opt/miniconda/bin
ENV_NAME=testEnvGPU
ENV_PATH=/mnt/nas/users/$(whoami)/.conda/envs/$ENV_NAME
source $CONDA_BIN_PATH/activate $ENV_PATH
python tensor.py
|
tensor.job이라는 이름으로 클러스터의 user home directory에 저장합니다.
sbatch에 대한 더 자세한 정보는 Slurm 공식 웹페이지를 참조하세요.
4. Slurm batch script 실행#
Conda environment를 만들 때처럼, sbatch 커맨드를 통해 job을 제출합니다. 할당되는 job 번호는 나중에 squeue를 통해 정보를 확인하거나 job을 취소할 때 이용되므로 기록해 놓아야 합니다.
터미널을 여러 개 띄운 다음 smap -i로 작업 현황을 확인하고, cat xxx.log이나 tail -f xxx.err으로 콘솔 출력이나 error를 확인합니다.
1
2
3
4
|
sbatch tensor.job
smap -i 1 # 작업 현황을 1초마다 갱신하여 보여줍니다. ctrl+c로 escape 할 수 있습니다.
cat tensor.log
tail -f tensor.err
|
로그 파일에 콘솔 아웃풋이 기록됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
2022-03-15 14:27:34.877232: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE4.1 SSE4.2 AVX AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-03-15 14:27:34.887611: I tensorflow/core/common_runtime/process_util.cc:146] Creating new thread pool with default inter op setting: 2. Tune using inter_op_parallelism_threads for best performance.
2022-03-15 14:27:38.063857: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
Epoch 1/5
1875/1875 [==============================] - 36s 19ms/step - loss: 0.2993 - accuracy: 0.9140
Epoch 2/5
1875/1875 [==============================] - 18s 10ms/step - loss: 0.1436 - accuracy: 0.9575
Epoch 3/5
1875/1875 [==============================] - 17s 9ms/step - loss: 0.1080 - accuracy: 0.9675
Epoch 4/5
1875/1875 [==============================] - 19s 10ms/step - loss: 0.0866 - accuracy: 0.9739
Epoch 5/5
1875/1875 [==============================] - 52s 28ms/step - loss: 0.0750 - accuracy: 0.9762
313/313 - 4s - loss: 0.0782 - accuracy: 0.9779
[0.078231580555439, 0.9779000282287598]
|
더 알아보기#
Submitting a slurm job script
SLRUM Job Examples
TensorFlow on the HPC Clusters